
TL; DR
seaborn.kdeplotでクラスごとに分布を描くとき、デフォルト引数のままだとクラスごとのサンプル数が違うと分布の大きさも違ってしまうkdeplotではデフォルトではcommon_norm=Trueになっており、全クラスの分布の面積の合計が1になるように分布が調整されるcommon_norm=Falseにするとクラスごとに分布を描いてくれるので、状況によっては設定したほうがいいかも
課題:クラスごとの分布の面積が違いすぎる
データの分布をノンパラ推定して図にしたいときにseabornのkdeplot系のメソッドを使う人は結構いると思います。hue引数を設定するだけでクラスごとに分布を描いてくれたりして便利ですよね。
# kdeplotのコード例 import seaborn as sns sns.kdeplot(data=df, x="x", hue="class")
ただ、hueに指定しているクラスごとのサンプル数に偏りがあるとき(例えば、一方のクラスはサンプル数が多いけど他方は少ない、みたいなとき)にシンプルにkdeplotを描くと面積がサンプル数に応じたものになります。
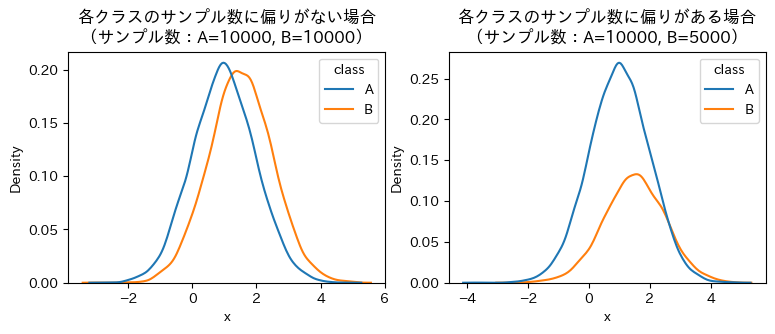
上の図はどちらのclassも分散が1の正規分布で、平均が少し違うだけです。データ生成時のサンプル数に差をつけてsns.kdeplot(data=df, x="x", hue="class")のように描くと、図のようにサンプル数に応じて分布の大きさが変わってしまいます。
▶(参考)データ生成時のコード
import numpy as np import pandas as pd n = 10000 np.random.seed(0) df = pd.concat([ pd.DataFrame({"class": "A", "x": np.random.normal(loc=1, size=n)}), pd.DataFrame({"class": "B", "x": np.random.normal(loc=1.5, size=n//2)}), ])
しかし、カーネル密度推定自体は確率密度関数の推定をするのでサンプル数に応じて密度や分布の面積が変わってくるのは奇妙です。 実際、matplotlibとscipyを使って自分でKDEを行ってkdeplotのようなものを描けば、クラスごとのサンプル数が不均衡でも面積の大きさに大差のない図ができます。
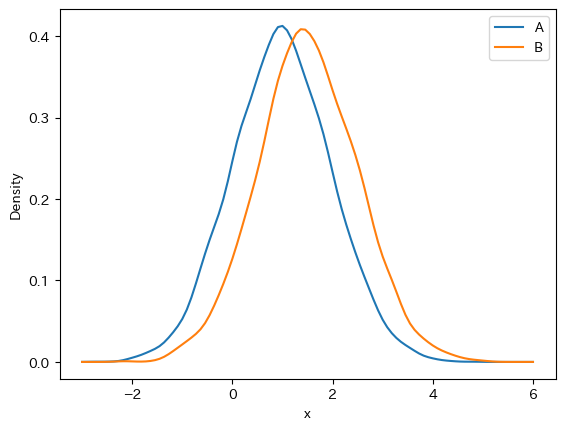
▶(参考)kdeしてplotするコード
import matplotlib.pyplot as plt from scipy.stats import gaussian_kde x_range = np.linspace(-3, 6, 100) fig, ax = plt.subplots() for class_label in df["class"].unique(): kernel = gaussian_kde(df.query(f"`class` == '{class_label}'")["x"]) ax.plot(x_range, kernel(x_range), label=class_label) ax.legend() ax.set(xlabel="x", ylabel="Density") fig.show()
調べてみたところ、サンプル数に応じて分布の大きさが変わるのはkdeplotの機能のようです。
対処法:common_norm=Falseにしよう
kdeplotにはcommon_normという引数があります。
common_norm : bool
If True, scale each conditional density by the number of observations such that the total area under all densities sums to 1. Otherwise, normalize each density independently.
(True の場合、すべての密度の総面積の合計が 1 になるように、各条件付き密度を観測値の数でスケールします。それ以外の場合は、各密度を個別に正規化します。)
デフォルトではTrueになっているcommon_normという引数で、複数のクラスごとの分布を出している場合もそれらの全体の面積の合計が1となるように正規化をかけているそうです。
なのでcommon_norm=Falseに設定すれば各クラスの密度の面積の合計が1になるように密度のスケールを扱ってくれます。
# common_normをFalseにすればよい import seaborn as sns sns.kdeplot(data=df, x="x", hue="class", common_norm=False)
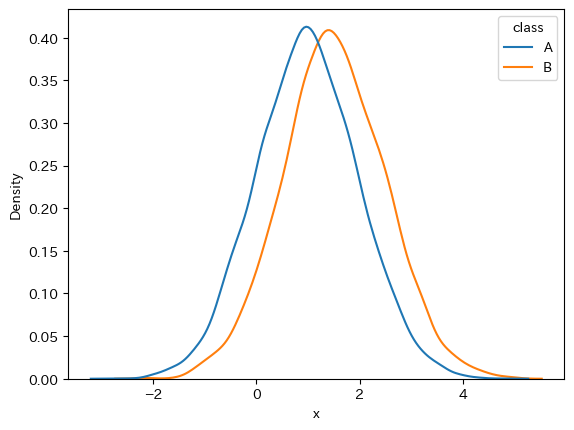
状況に応じて引数を使い分けるべきでしょうが、クラスごとに分布の形状を比較したいときはcommon_norm=Falseにしたほうがよさそうに思えます。