タイトル通りです。なんか便利そうなの見つけたので何ができるか簡単にメモしておきます
メソッド紹介
{summarytools}はRにおいてデータの要約統計量や分布などを簡単に一覧で見られるメソッドたちを提供するパッケージです。
freq()
度数分布表を出してくれます
> mtcars$gear %>% freq() Frequencies mtcars$gear Type: Numeric Freq % Valid % Valid Cum. % Total % Total Cum. ----------- ------ --------- -------------- --------- -------------- 3 15 46.88 46.88 46.88 46.88 4 12 37.50 84.38 37.50 84.38 5 5 15.62 100.00 15.62 100.00 <NA> 0 0.00 100.00 Total 32 100.00 100.00 100.00 100.00
{summarytools}はview()というメソッドも用意しており、これを使うとhtml形式でもっとリッチな表現をしてくれます
dfSummary()
データフレームの各カラムの情報を要約します
dfSummary(iris) %>% view()

Pythonでいうpandas-profilingみたいなやつですね
Rだと{skimr}パッケージのskim()が似てますね
> library(skimr) > skimr::skim(iris) ── Data Summary ──────────────────────── Values Name iris Number of rows 150 Number of columns 5 _______________________ Column type frequency: factor 1 numeric 4 ________________________ Group variables None ── Variable type: factor ───────────────────────────────────────────────────────────────────────────────────────── skim_variable n_missing complete_rate ordered n_unique top_counts 1 Species 0 1 FALSE 3 set: 50, ver: 50, vir: 50 ── Variable type: numeric ──────────────────────────────────────────────────────────────────────────────────────── skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100 hist 1 Sepal.Length 0 1 5.84 0.828 4.3 5.1 5.8 6.4 7.9 ▆▇▇▅▂ 2 Sepal.Width 0 1 3.06 0.436 2 2.8 3 3.3 4.4 ▁▆▇▂▁ 3 Petal.Length 0 1 3.76 1.77 1 1.6 4.35 5.1 6.9 ▇▁▆▇▂ 4 Petal.Width 0 1 1.20 0.762 0.1 0.3 1.3 1.8 2.5 ▇▁▇▅▃
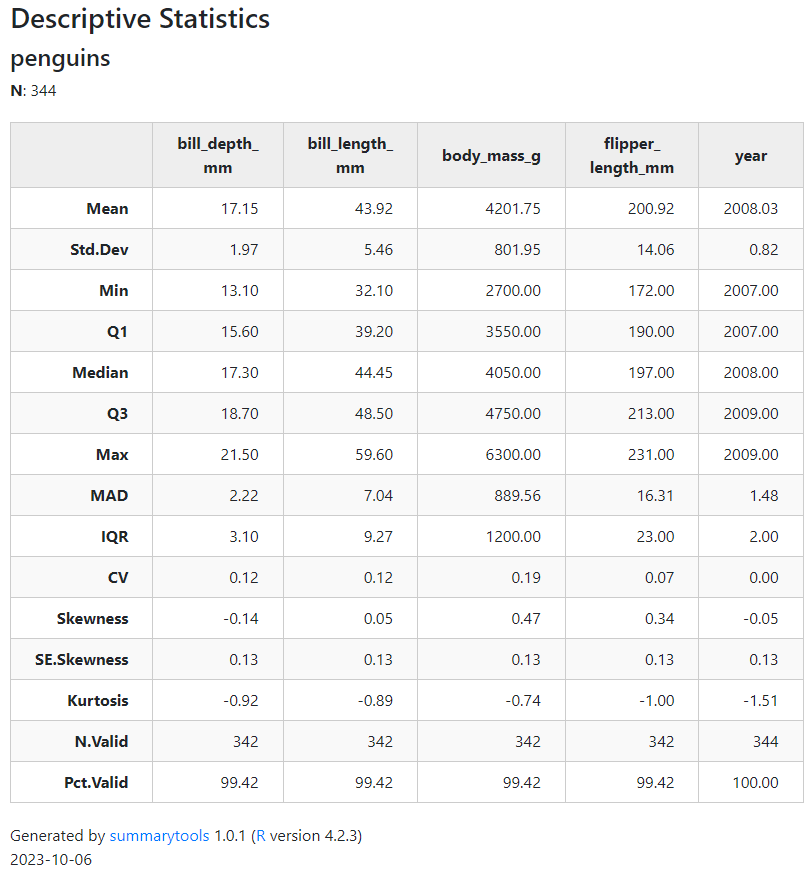
descr()
記述統計量を出します
install.packages("palmerpenguins") library(palmerpenguins) # なんとなくpenguinsデータセットを利用 descr(penguins) %>% view()
ctable()
クロス表を出してくれます。 カイ二乗値やオッズ比などを下に表示するオプション機能もあります。
ctable( x = tobacco$gender, y = tobacco$smoker, chisq = TRUE ) %>% view()
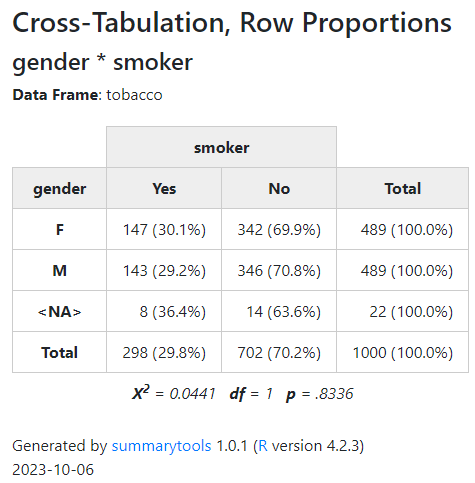
クロス表をたくさん使うときは便利そう
参考サイト
- GitHubリポジトリ
- 公式のドキュメント ← かなり丁寧に作られてておすすめ