最近まで知らなかったのでメモ。
テキストのコピーの場合
そもそもコピーはどう実装するのか、文法の基礎を確認していきます。
以前であればdocument.execCommand("copy")を使っていたのですが非推奨になったようです。今はnavigator.Clipboardを使うようです。
テキストをコピーさせることに特化したwriteText()メソッドを使うと次のように書くことができます。
navigator.clipboard.writeText("Hogehoge").then(() => {
console.log("success");
}, (msg) => {
console.log(`fail: ${msg}`);
});
テキスト以外のコピーの場合
write()メソッドを使えば任意のオブジェクトをコピーさせることができます。
write() の使い方
write()はClipboardItemオブジェクトの配列を受け取ります。そしてClipboardItemはBlobオブジェクトを受け取ります。
つまりどういうことかというと、次のように書きます。
const text = "ほげほげ"
const blob = new Blob([text], { type: "text/plain" });
const data = [new ClipboardItem({ "text/plain": blob })];
navigator.clipboard.write(data).then(
() => { console.log("success"); },
(msg) => { console.log(`fail: ${msg}`); }
);
HTMLをコピーする
text/htmlのblobを用意してやることで、htmlで装飾された文章のコピー&貼り付けが実現できます。
メモ帳のようなテキストエディタに貼り付けた際はtext/plainで渡した文字列しか貼り付けられないため、貼り付けたいhtmlをtext/htmlにしてそのinnerTextに相当するものtext/plainに入れると良さそうです。
SlackなどのWYSIWYGエディタに貼り付ける際もtext/htmlだけでなくtext/plainも付けてやる必要があるようです(htmlのblobだけでは貼り付けても何も表示されませんでした)。
const copyHtml = (html, plainText) => {
const blobHtml = new Blob([html], { type: "text/html" });
const blobPlain = new Blob([plainText], { type: "text/plain" });
const data = [new ClipboardItem({ "text/html": blobHtml, "text/plain": blobPlain })];
navigator.clipboard.write(data).then(
() => { console.log("success");},
(msg) => { console.log(`fail: ${msg}`);}
);
};
copyHtml('<a href="https://google.com/">Google</a>', 'Google')
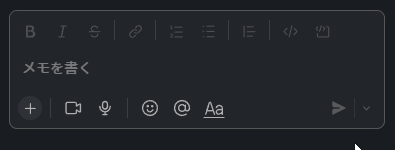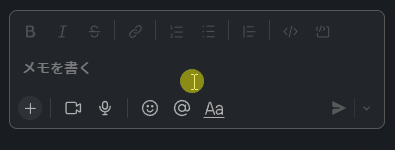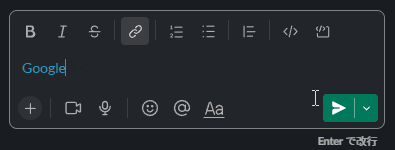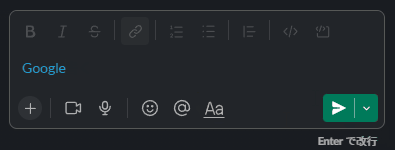
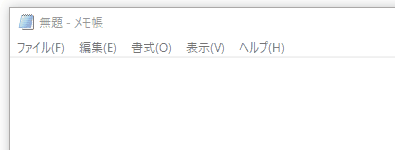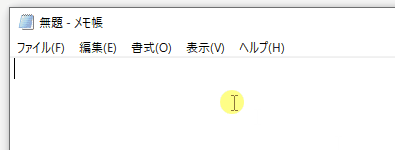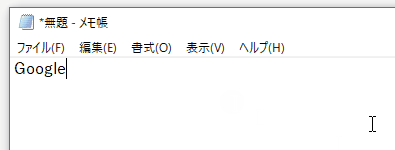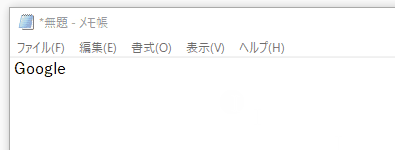
画像をコピーする
blobを取得するために画像のURLに対してfetchする必要があったりとやや面倒ですが、以下のように書くことができます。
const img = document.getElementById("img");
const responsePromise = await fetch(img.src);
const blob = responsePromise.blob();
const data = [new ClipboardItem({ "image/png": blob })];
navigator.clipboard.write(data).then(
() => { console.log("success"); },
(msg) => { console.log(`fail: ${msg}`); }
);
参考までにhtml全体も載せておきます
(fetchする際のCORSの問題を回避するためbase64で画像を載せています)
<html lang="en">
<head></head>
<body>
<img id="img" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEAAAABACAYAAACqaXHeAAABhWlDQ1BJQ0MgcHJvZmlsZQAAKJF9kT1Iw0AcxV9TpSJVByuIOGSoDmJBVMRRqlgEC6Wt0KqDyaVf0KQhSXFxFFwLDn4sVh1cnHV1cBUEwQ8QVxcnRRcp8X9JoUWMB8f9eHfvcfcOEOplppodE4CqWUYyFhUz2VUx8Ao/AujFAMYkZurx1GIanuPrHj6+3kV4lve5P0ePkjMZ4BOJ55huWMQbxDObls55nzjEipJCfE48btAFiR+5Lrv8xrngsMAzQ0Y6OU8cIhYLbSy3MSsaKvE0cVhRNcoXMi4rnLc4q+Uqa96TvzCY01ZSXKc5jBiWEEcCImRUUUIZFiK0aqSYSNJ+1MM/5PgT5JLJVQIjxwIqUCE5fvA/+N2tmZ+adJOCUaDzxbY/RoDALtCo2fb3sW03TgD/M3CltfyVOjD7SXqtpYWPgL5t4OK6pcl7wOUOMPikS4bkSH6aQj4PvJ/RN2WB/luge83trbmP0wcgTV0t3wAHh8BogbLXPd7d1d7bv2ea/f0AauRypMbk75EAAAAGYktHRAD/AP8A/6C9p5MAAAAJcEhZcwAALiMAAC4jAXilP3YAAAAHdElNRQfnAwcOFxrvnZMVAAAAGXRFWHRDb21tZW50AENyZWF0ZWQgd2l0aCBHSU1QV4EOFwAABNxJREFUeNrtmmtMm2UUx/9vgXIrg9K15TpooYzbVstlAyEruwYz2YUEzYxOlxHNRIMxM9s3TWaWJRo1w/jBuGg2zNw+EJTNDxsMsJPbQIvAKmPcaaHc1rXcSi+vH+reUto6SEoTw3M+PT3nOX2f5/ee95zztC9F0zSNTSwsbHIhAAgAAoAAIAAIAAKAACAACAACgAAgAAgAAoAAIAAIAAKAACAACAACgADYNOK7nsn6uUXkfPILACCLH4Sr54owMf0U1Y0q1Kq00BnNyI/n4mieBLLkWLe+72THoPzVPIxpn+DXpkdoUGkxZDBiBz8YB3dGo/DFZHCC/J2ub7FY0dY9jMbOYbQO6dBvMMLs5o+9W+X7II7lexbASmmfWkCTcgBnb3RAZ7Iy+puqKdxUTeFSURqOyNNd+tZ0T0AuHcPJK787bEChMUCh+Ru3/xzD1+8dQHCgHYLJZMGlSgWu92ifuzYe2wdstu/GPwKllQ+gM1khCWFDxPFzsJ2v6cHI+KxLP82iGa99Z9t8mB8Lsq2BDvZW7RxqW/scdA3tj5nN89g++OGtHNSdK0TFKzKHeRUlMtRfKEaMkOv5R8DJmQJunJEjRRwBmqbR8tcQTl9rY+x17f04VRTu1r+iRIaC7ET4sFgY1szg2Fd1MFptIVHfpcbRAnsE3escZcbv7hFjV3ocACCSH4oTPRoGzviMAb4+LO8kwTM5cUgRRwAAKIpCrlSEI4n2Dd/tGnfrW5LCx/7dSfBh2ZYQF8XD6y9EMva+mXmH+aO6JWYcER7iYIsTcOzRtcpvQwEkRIU56WRie+JRzi5i2WRx6ZslETrponn2jcyvyCsAkMAPYsbqab2DbUhrYMbhIQHeAxAcyHbScVbpzBbXAEI5zgt9Fg2u5FBmPDP+RjGA5s5BqLU63G3uxU8PJxlbbnrsxpXB1bKwZHIulfNLDp/93WRjXxa1rmvlSkX4cGgaX9wfhM5kdcg1z+TjQ9uRlhjpPQC9IzM4mOOoa+2bsi9ayPnPu7quUKUo7M8S42elGv1zy4gL9sOs0YLt3ADkSfjYmyFCUrxwYxuh1fLtg1HkpI0gI9UWdoqOftwZ1tnDVhrtsY5NO6NH8eV7MFppfCQX41RRtvc7wdVipoGT3zdD4N8GFkVhYslsD30Whb2ZYo8BMMwvMSXys8YB3FKqIeT4/1uBAG4wG2mxXMgzxIgShHknCZbttt35SaPFYfMA8GWJDALeFo8BSNwmwMXDqcxn1VMjGtR6NKj1qB/To6p3Ghdq+3D48ztQDUx4B0D+zm2oKd+H0sxoiDh+kISw8aY0AlVlchRkSzx6aPmt4zGu3e9/7jyjlcbl6j/W/L3Uet4TXHmgAYArb+xCrlS04Se2JuUgSittWf94Eg/vF2dDwNsCFkXBStNYWFxGk3IQH1R12s8qnx5HUAB7YyPAW+9Y3m6z3/m3X5YhYmsoWBTFVAdOkD/2ZCasuaf43/0eMD23vKLPMLo+nT4cYcYvibhu+w+PVgFvSX6yEAqNrd09/2MLyg4kI0YQCpqm8US/CEX3GK732LvB04U7vFMGvSXH5GloeTSJ+jE9BudMOFvd5XJebKAfLp7IQmrC2rtBirwsvcmFACAACAACgAAgAAgAAoAAIAAIAAKAACAACAACYNPJPwjAmOOBloBXAAAAAElFTkSuQmCC" />
<button id="copyButton">Copy</button>
<script>
const copyImage = async () => {
const img = document.getElementById("img");
const responsePromise = await fetch(img.src);
const blob = responsePromise.blob();
const data = [new ClipboardItem({ "image/png": blob })];
navigator.clipboard.write(data).then(
() => { console.log("success"); },
(msg) => { console.log(`fail: ${msg}`); }
);
};
const button = document.getElementById("copyButton");
button.addEventListener("click", copyImage);
</script>
</body>
</html>
上記htmlのページからSlackに貼り付ける際は次のようになります